介绍
链表的类似于一个连着一个的圆环。在链表中,要想访问某个节点,必须通过他的上一节点来访问。
Java实现
1 | package com.algs.base; |
GitHub:https://github.com/AlbertKnag/algs-practice
下一篇:基础数据结构02:队列
链表的类似于一个连着一个的圆环。在链表中,要想访问某个节点,必须通过他的上一节点来访问。
1 | package com.algs.base; |
GitHub:https://github.com/AlbertKnag/algs-practice
下一篇:基础数据结构02:队列
Eclipse项目中的静态资源采用webpack来打包,在项目中的webapp目录下会生成node_modules目录,里面包含node相关模块。由于资源文件较多,会造成Eclipse编译缓慢,另外这些文件不需要发不到运行服务器上,且不需要做版本控制。
选中项目右键-properties,如下图所示
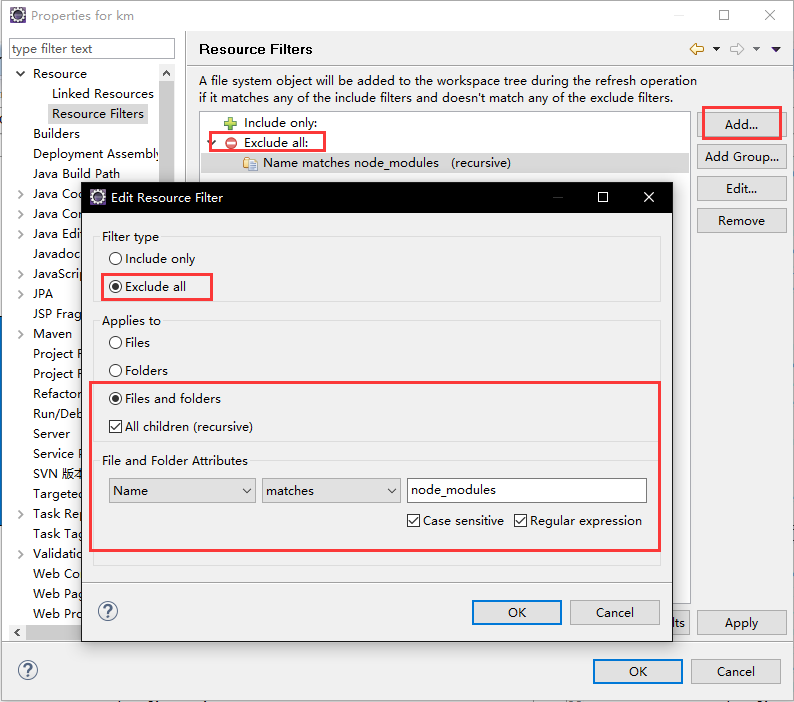
当使用Eclipse中的SVN来来就行版本控制时,选择node_modules目录后,发现添加至svn:ignore为灰色,不可用,无法忽略相关文件。可以通过如下配置来解决该问题。
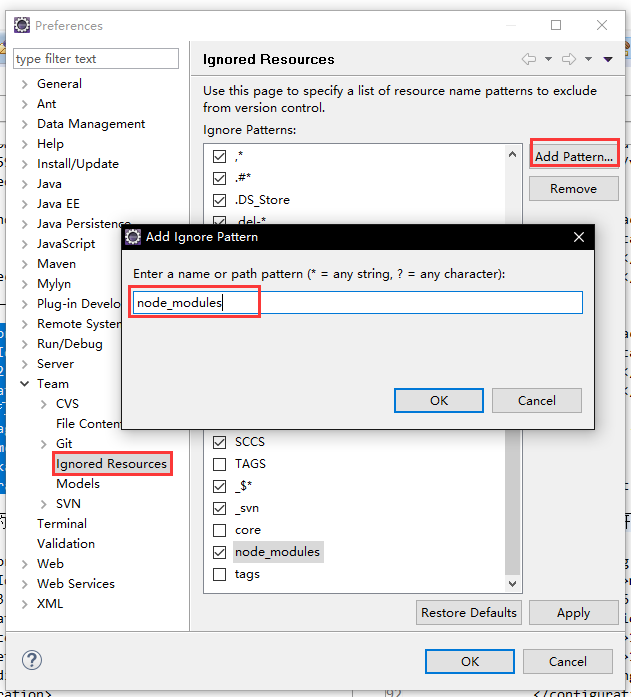
在项目的maven pom.xml中build下的配置如下
1 | <plugin> |
创建数据库的索引,可以选择单列索引,也可以选择创建组合索引。
遇到如下这种情况,用户表(user)与部门表(dept)通过部门用户关联表(deptuser)连接起来,如下图所示:

问题就是,在这个关联表中该如何建立索引呢?
针对该表,有如下四种选择:
对关联表的查询,有如下四种情况:
1 | -- 一、人员查所属部门用and方式 |
























通过上面的实际测试结果可以得出如下结论:针对于该关联表分别针对于user_uuid与dept_uuid建立单列索引idx_user,idx_dept最优。
其中索引idx_user适用与通过人员ID查询出该人员所在的部门;索引idx_dept适用与通过部门查询出该部门下所属的人员。

在这篇之前,对常见的8中排序算法进行了梳理,《算法》第四版中的这一张图对各种排序算法的性能特点做了总结。

补充冒泡排序:稳定、原地排序、时间复杂度为n²,空间复杂度为1。
其它:
GitHub:https://github.com/AlbertKnag/algs-practice
(包含Java版与Javascript版所有排序算法样例代码)
上一篇:排序算法08:优先队列与堆排序
堆排序一种是基于二叉堆的排序。本文将从优先队列讲起,循序渐进的实现堆排序。这也是《算法》第四版上讲解堆排序的大致章节结构。另外,本文所有的图都来自于此书。
普通队列是一种先进先出的数据结构,先放进队列的元素取值时优先被取出来。而优先队列是一种具有最高优先级元素先出的数据结构,比如每次取值都取最大的元素。
优先队列有两个核心方法,一个是insert(val)向队列中添加元素,另外一个是delMax()删除最大元素(优先级最高的)并返回。可以考虑使用数组来存储优先队列的数据。
优先队列有如下三种实现方式:

优先队列可以使用一棵堆有序的二叉树来解决。什么叫做堆有序呢?当一棵二叉树的每个几点都大于它的两个子节点时,它被称为堆有序。那么,根节点就是堆有序的二叉树中的最大节点。
二叉堆可以使用数组来存储。为了方便起见,根节点放在位置1处(位置0不使用),它的两个子节点分别放在位置2和位置3。同理可知,在一个堆中,位置k的节点的父节点的位置为k/2,而它的两个子节点的位置则分别为2k和2k+1.我们就可以这样在树的上下移动:访问a[k]节点的上一层就令k等于k/2,向下一层就令k等于2k或2k+1.
如下图所示:

使用二叉堆,我们就能实现对数级别的插入元素和删除最大元素。
当调用优先队列的insert方法时,我们首先把元素放置到数组的结尾,然后再把该元素上浮到正确的节点,最终形成堆有序状态。
代码如下:
1 | //下标为k的元素上浮到正确位置 |
当调用优先队列的delMax方法时,我们下标为1的元素(最大元素)和数组最后一个元素交换,返回最大元素,数组长度减去1,即删除最后一个元素。此时的位置1元素不一定是最大元素,就需要下沉到正确位置,重新构造有序堆。
代码如下:
1 | //下标为k的元素下沉到正确位置 |
堆有序化示例图:

堆的操作示例图:

理解了实现堆有序的上浮和下沉两种方法,优先队列的实现就轻而易举了,代码如下:
1 | /** |
示例图:

理解了优先队列,堆排序的逻辑十分简单。第一步:让数组形成堆有序状态;第二步:把堆顶的元素放到数组最末尾,末尾的放到堆顶,在剩下的元素中下沉到正确位置,重复操作即可。
代码如下:
1 | /** |
示例图:

1 | /** |
1 | package com.algs; |
GitHub:https://github.com/AlbertKnag/algs-practice
上一篇:排序算法07:三向快速排序
下一篇:排序算法09:总结
在上一篇排序算法06:快速排序中,可以知道,快速排序不停的递归切分数组。在有大量的重复元素情况下,这样的切分存在巨大的改进空间。三向切分的快速排序就是为了提升在有大量重复元素情况下快速排序的性能。
快速排序把数组切分为两部分,分别对应与小于,大于切分元素的数组元素。而三向切分将数组切分为三部分,分别对应小于,等于,大于切分元素的数组元素。
三向切分的快速排序的算法逻辑为:从左到右遍历数组一次,维护一个指针lt使得a[lo..lt-1]中的元素都小于v,一个指针gt使得a[gt+1..hi]中的元素都大于v,一个指针i使得a[gt..i-1]中的元素都等于v,a[i..gt]中的元素都还未确定。
三向切分的示意图:

1 | function quick3way(a,lo,hi) { |
三向切分的轨迹:

1 | /** |
1 |
|
GitHub:https://github.com/AlbertKnag/algs-practice
上一篇:排序算法06:快速排序
下一篇:排序算法08:优先队列与堆排序
快速排序是一种分治的排序算法。排序逻辑为:先挑一个元素来切分数组,最终让该元素的左侧都小于该元素,右侧的所有元素都大于该元素。递归的让左侧和右侧分别执行该操作,最终让整个数组变得有序。
快速排序示意图:

咋眼一看快速排序跟归并排序很像,其实区别挺明显的。归并排序将数组分成两个子数组分别排序,并将有序的子数组归并以将整个数组排序;而快速排序将数组排序的方式则是当左右两个数组有序时整个数组为自然有序状态。
快速排序的核心在于数组的切分。切分的逻辑为,维护两个指针i和j,i从前往后移动,j从后往前移动。最终让切分元素的左侧都小于切分元素,右侧都大于切分元素。
切分示意图如下:

Javascript代码如下:
1 | /** |
一次切分的切分轨迹如下:

切分完成了排序就比较简单了,代码如下:
1 | /** |
1 |
|
1 |
|
GitHub:https://github.com/AlbertKnag/algs-practice
上一篇:排序算法05:归并排序
下一篇:排序算法07:三向快速排序
归并排序的算法逻辑为把两个有序的数组归并为一个有序的数组。
举个例子,对于一个长度为8的数组,有两种归并方式
自顶向下的归并:
自底向上的归并:

1 | /** |
下面这张原地归并轨迹的样例图来自于《算法》第四版,左侧为arr,右侧为temp数组

1 | /** |



1 | /** |

1 | /** |
1 | package com.algs; |
GitHub:https://github.com/AlbertKnag/algs-practice
上一篇:排序算法04:希尔排序
下一篇:排序算法06:快速排序
从上一篇《插入排序》可以知道,当最小元素恰好在最后一个时,需要移动的次数为N-1。当一个从大到小排列的数组使用插入排序变成从小到大排列时,需要比乱序状态下耗费更多的时间。原因为插入排序是从后往前一位一位的往前交换,如果能把靠后的较小元素只交换(移动)一次就插入到靠前位置,则能有效的缩短排序时间。希尔排序就是这样一种算法。
希尔排序通过一个序列让靠后的元素一次性移动到前面,最后使用插入排序让数组变成有序状态。
举个例子。长度为100的数组,挑选出[1,10,20,50]这么一个序列,这个数列的含义就是每次元素移动的间隔。
下图为《算法》第四版上希尔排序排序轨迹样例:

这张图是对SHELLSORTEXAMPLE字符序列排序,序列为13、4、1。
可视化效果:这里
1 |
|
1 |
|
GitHub:https://github.com/AlbertKnag/algs-practice
上一篇:排序算法03:插入排序
下一篇:排序算法05:归并排序
步骤:
排序演示:

可视化效果:这里
1 |
|
1 | package com.algs; |
GitHub:https://github.com/AlbertKnag/algs-practice
上一篇:排序算法02:选择排序
下一篇:排序算法04:希尔排序
缺失模块。
1、请确保node版本大于6.2
2、在博客根目录(注意不是yilia根目录)执行以下命令:
npm i hexo-generator-json-content --save
3、在根目录_config.yml里添加配置:
jsonContent:
meta: false
pages: false
posts:
title: true
date: true
path: true
text: false
raw: false
content: false
slug: false
updated: false
comments: false
link: false
permalink: false
excerpt: false
categories: false
tags: true