最近使用Elasticsearch来做异常监控的存储,写了不少ES的索引操作,以及对数据的增删改查操作,记录一下,以备不时之需。
1 |
|
最近使用Elasticsearch来做异常监控的存储,写了不少ES的索引操作,以及对数据的增删改查操作,记录一下,以备不时之需。
1 |
|
1.下载地址:https://www.elastic.co/cn/start
复制下载链接
1 | 下载资源 |
1 | cd elasticsearch-7.3.0-linux-x86_64 |
当使用elasticsearch-head插件访问elk时,需要设置允许跨域访问
1 | vim config/elasticsearch.yml |
默认情况下,启动elk服务后,其它服务器是无法访问elk服务的(telnet不通),只允许本地访问。
需要做如下配置:
1 | vim config/elasticsearch.yml |
此时,启动会报如下两个错误:
1 | ERROR: [2] bootstrap checks failed |
对于第一个配置,root用户权限下,增加如下配置:
1 | vi /etc/sysctl.conf |
对于第二个错误,增加如下配置:
1 | vim config/elasticsearch.yml |
作者公众号:
团队中做code review有一段时间了,最近一直在思考一个问题,抛开业务逻辑,单纯从代码层面如何评价一段代码的好坏?
好和坏都是相对的,一段不那么好的代码经过优化之后,如何标准化的给出重构前后的差异呢?
我们所有的代码都跑在计算机上,计算机的核心是CPU和内存。从这个角度来看,效率高的代码应当占用更少的CPU时间,更少的内存空间。
因此,问题就演变为优化一段代码,到底优化了多少CPU的使用以及内存空间的使用?
在数据结构与算法中,常用大O来表示算法的时间复杂度,常见的时间复杂度如下所示:(来源《算法》第四版)

时间复杂度这个东西,是描述一个算法在问题规模不断增大时对应的时间增长曲线。所以,这些增长数量级并不是一个准确的性能评价,可以理解为一个近似值,时间的增长近似于logN、NlogN的曲线。如下图所示:

上面是关于时间复杂度的解释,下面通过具体样例来看看代码的时间复杂度
代码一:
1 | (function count(arr=[1,2,3,4,5,6,7,8,9,10]){ |
这是一段求数组中数字总和的代码,我们粗略估计上述代码在CPU中表达式运算的时间都是一样的,计为avg_time,那么我们来算一下上面的代码需要多少个avg_time.
首先从第二行开始,表达式赋值计为1个avg_time;代码的3、4、5行分别要运行10次,其中第三行比较特殊,每次运行需要计算arr.length以及i++,所以这里需要(2+1+1)*10 个avg_time;总共就是(2+1+1)*10+1=41个avg_time
接着,我们来对上面的代码优化一番,如下所示:
代码二
1 | (function count(arr=[1,2,3,4,5,6,7,8,9,10]){ |
不难算出,优化后的代码只耗费了1+1+(1+1)*10=22个avg_time,代码二相对于代码一,节约了41-22=19个avg_time,代码性能提升19/41=46.3%!
1.灵活使用break、continue、return
这三个关键字一般用在减少循环次数,达到目的,立即退出。如下所示:
1 | (function check(arr=[1,2,3],target=2){ |
2.空间换时间
常见的做法是利用缓存,把上次的计算结果存起来,避免重复计算。
3.更优的数据结构与算法
根据不同的情况选择合适的数据结构与算法,例如,如果需要频繁的从一组数据中通过关键key查询出数据,如果要从json对象和数组中选择,那么可以优先考虑使用json对象来避免数组的遍历查询。
评价一段代码,除了看它执行需要多少时间,还需要看看需要多少空间,谈到代码的空间占用,必须就得知道JS的内存管理
JS的内存管理分为三部分:
内存分配。
这里包含包含代码本身以及静态数据与动态数据所需要的内存,其中代码本身与静态数据会分配在stack上,可变的动态数据会分配在heap上
使用分配的内存。
内存回收。
这里,放一张JS Runtime的图

是指stack中内存的分配,基础数据类型的数据就放在stack中。另外,stack是有固定大小的,超过stack的长度,就会报错,所以必须得节约着用。
1 | // 故意来一次爆栈体验 |
我们是怎么达到爆栈目的的呢?因为所有的函数调用,在内存中都存在一个函数调用栈,我们不断无结束条件的递归调用,最终撑破了stack。
如图所示:

可能你会问怎么证明函数调用栈的存在呢?请看如下代码:
1 | function second() { |
从上面的运行结果可以看出函数调用栈的顺序,start先入栈,接着first,最后second;打印顺序为首选打印second,最后打印start;满足栈的先进后出的数据结构特性。
了解上面知识点的核心目的还是在于指导我们写出更优的代码,我们知道基本数据类型都放在栈中,对象都放在堆中。另外,通过《JavaScript权威指南》第六版第三章可以知道,js中的数字都是双精度类型,占64位8个字节的空间,字符占16位2个字节的空间。
有了这个知识,我们就可以估算出我们的代码大致占用了多少内存空间。
这些毕竟都是理论知识,不禁要怀疑一下,的确是这样的吗?下面我们利用爆栈的原理,通过代码实际瞧瞧
1 | let count = 0 |
我们知道一个数字占8个字节,栈的大小固定;稍微变更一下代码
1 | let count = 0 |
那么我们可以利用如下方法算一下栈的总大小
1 | N = 栈中单个元素的大小 |
注:不通环境可能结果不太一样
接下来,我们来确定一下数字类型是否占8个字节空间
1 | let count = 0 |
计算一下Number的内存占用大小
1 | // 总的栈内存空间/栈中元素数量 = 单个栈元素大小 |
经实际验证,在Chrome、Safari、Node环境下,不论变量的值是什么类型,在stack中都占8个字节。对于字符串貌似跟预期不太一样,不论多长的字符串实践表明在stack中都占8个字节,怀疑浏览器默认把字符串转换为了对象,最终占用heap空间
是指heap中内存的分配,所有对象都放在heap中,stack中只放对象的引用。
这里有一篇数组占用多少内存空间的文章:How much memory do JavaScript arrays take up in Chrome?
低内存占用,从静态内存分配方面可以考虑,尽量少的使用基础类型变量;从动态内存分配的角度,让代码更简洁、不要毫无节制的new一个对象、少在对象放东西;
下面是一些小技巧:
1.三目运算符
1 | // 条件赋值 |
2.直接返回结果
1
2
3
4
5
6
7if(a===1){
return true
}else{
return false
}
// 可简化为
return a===1
一时半会儿想不到好的样例,上面的样例至少节约了代码的空间占用!……欢迎评论补充……
我的理解是,当函数调用栈为空时,占用的占内存随之清空;只有堆内存中的数据才需要通过垃圾回收机制来回收。
常见的垃圾回收算法如下:
引用计数
对没有对象的引用计数,如果没有任何外部引用时,则清除该对象;引用计数算法有一个弊端就是无法清除循坏依赖的对象。
标记清除:
每次回收,从根对象开始遍历,能遍历到的对象则记为可用,不能遍历到的对象则为需要垃圾回收的对象。此种算法能够解决对象循环依赖的问题。
综合算法:
实际上垃圾回收是一个很复杂的过程,垃圾回收器会根据内存的不通情况采取不同的垃圾回收算法,来实现效率的最大化。
这里有一篇垃圾回收的文章:A tour of V8: Garbage Collection 已经被翻译为了中文,点进去就知道了。
从上面的垃圾回收机制不难看出,当某些情况内存无法被回收且不断增加时,内存溢出就会产生。下面是几种常见的会有内存溢出风险的代码。
1.控制全局变量
从垃圾回收的原理我们可以知道,全局变量肯定是不会被回收的。所以我们应当尽量把数据绑定到全局变量上,更应该避免通过用户操作持续的增加全局变量数据的大小。
另外还需要特别注意意外的全局变量产生,例如:
1 | function foo(arg) { |
2.setInterval注意内存占用
由于setInterval一直处于活动状态,造成它所依赖的数据一直无法回收。特别容易出现数据越积越多情况
3.注意闭包
闭包里依赖了主函数的数据,为了让闭包续继访问到数据,必须避免当主函数退出时,回收闭包依赖主函数的变量所对应的数据,从而带来内存溢出风险。
资料:

2018年是十分重要的一年,忙碌的一年,有收获的一年。
今年的3.15离开奋战了将近四年的中国软件,入职一家互联网公司,开启职业生涯第三段征程。
今年都做了些什么?头脑里第一个冒出来的就是今年工作中做的事儿,今年是转行的第一年,不敢有丝毫的怠慢,大部分精力都投入到了工作中。

近三年的时间里,断断续续的写了100多篇文章,很少有收到对文章的评论。因此,时不时总会感受到一丝丝的失落。这时,只能把它当作个人的总结归纳与成长。
看到上面这条评论,很欣慰……
平时自己也总读其他作者的文章,悄悄的去,然后悄悄的走。从今天开始,我觉得今后不论文章怎么样,多少都应该给原创者表示表示,留下点什么。一个赞、一个顶、一个评论,以示对作者无私分享的感激,鼓励他继续创作下去。
在CSDN上,之前觉得应当尽量只发一些技术类的文章,个人所思所想放在自己独立博客的一亩三分地上。甚至在最近,发现CSDN不断没落下去,广告奇多,准备放弃CSDN了。但是,看到这条评论后,我觉得还是应该留下来,同时,把有价值的所思所想分享出来,以让更多人看到为目的。对于技术分享,影响的范围可能只是一个bug的解决,而思想感悟的分享,影响面则会更大。而且,封闭的思想,注定也会是孤独的……
回想起决定写博客的初心,是想“把自己知道的东西分享出来,总会帮助到一些人”。现在看来,总会帮助到一些人这一宏大愿景,值得更坚定不移的执行下去。
每一条评论都是我继续分享下去的源动力,Thanks!
发现客户端选择下单时间后,提交订单并查看订单,在订单上显示的之前用户之前选择的时间存在1-N小时不等的差值。
例如:在下单页选择的2018-01-01 10:00,下单完成后,在订单详情页上面显示为2018-01-01 09:00,与实际的相差1小时。
结合代码分析,发现当用户选择完时间后,会把选择的时间字符串调用getTime方法转换为毫秒数传给后端,后端再转换回时间字符串,在这个转换过程中,时间出现了差值。
最终,排查出问题原因为时区问题。还是以上面的样例为范本。当客户端的时区为东京,服务器端的时区为北京就能完美复该问题。
使用getTime方法获取时间的毫秒数时,实际上的获取当前的格林威治时间与1970年1月1日之间的毫秒数。东京时间为东9区,比标准时间快9个小时,所以在东京时区下时间转毫秒数就会减去9个小时才会为标准时间。此时北京时间与标准时间为8个小时的时差,客户端用东京时间转换为毫秒数(减9个小时),服务器端再用北京时间把毫秒数转换为时间字符串(加8个小时),此时就出现了时间差。
1 | function getTruthTime (time) { |
在前后端分离的开发场景下,不可避免的会有前后端联调。在联调阶段,经常会遇到各式各样的问题,比如乱码问题、前端传的数据(字符串、数组、Json对象)后端无法正常解析等问题。
本文希望从源头着手,理清问题的根本原因,快速定位出现问题的位置,让前后端联调得心应手,让甩锅不再那么容易……
之所以这里会介绍一下HTTP协议,是因为前后端联调离不开HTTP。了解了HTTP协议,有助于更好的理解数据传输的流程,以及更好的分析出到底是在哪个环节出了问题,方便排查。
首先,http是一个无状态的协议,即每次客户端和服务端交互都是无状态的,通常使用cookie来保持状态。
下图为http请求与响应的大致结构(本部分配图均来自于《HTTP权威指南》):

说明:
从上图中可以看出,HTTP请求大致分为三个部分:起始行、首部、主体。在请求起始行里,表面了请求方法、请求地址以及http协议的版本。另外,首部即是我们常说的http header。
下面是常用的HTTP请求方法以及介绍:

说明:
HTTP传输的内容类型与编码是由Content-Type来控制的,客户端与服务端通过它来识别与解析传输内容。
常见的Content-Type:
| 类型 | 说明 |
|---|---|
| text/html | html类型 |
| text/css | css文件 |
| text/javascript | js文件 |
| text/plain | 文本文件 |
| application/json | json类型 |
| application/xml | xml类型 |
| application/x-www-form-urlencoded | 表单,表单提交时的默认类型 |
| multipart/form-data | 附件类型,一般为表单文件上传 |
前面六个为常见的文件类型,后面两个为表单数据提交时类型。我们ajax提交数据时一般为Content-Type:application/x-www-form-urlencoded;charset=utf-8,以此声明了本次请求的数据格式与数据编码方式。需要额外说明的是,application/x-www-form-urlencoded此种类型比较特殊,数据发送时会把表单数据拼接成类似于a=1&b=2&c=3的格式,如果数据中存在空格或特殊字符,会进行转换,标准文档在
这里,更详细的在 [RFC1738]可见。
相关资料:
前后端联调之所以需要了解这部分,是因为在前后端的数据交互中,经常会碰到乱码的问题,了解了这块内容,对于解决乱码问题就手到擒来了。
一图胜千言:

在图中,charset的值为iso-8859-6,详细介绍了一个文字从编码到解码,再到显示的完整过程。
相关资料:
前端部分负责发起HTTP请求,前端常用的HTTP请求工具类有jquery、axios、fetch。实际上jquery与axios的底层都是使用XMLHttpRequest来发起http请求的,fetch属于浏览器内置的发起http请求方法。
前端ajax请求样例:
1 | <html> |
相关资料:
这里使用Java平台为样例来介绍后端是如何接收HTTP请求的。在J2EE体系下,数据的接收与返回实际上都是通过Servlet来完成的。
Servlet接收与返回数据样例:
1 | package com.demo.servlet; |
相关资料:
| 请求方式 | method | 请求Content-Type | 数据格式 | 后端收到的Content-Type | 能否通过getParameter获取数据 | 能否通过inputStream获取数据 | 后端接收类型 |
|–|
| XHR | Get | 未设置 | url传参 | null | 能 | 否 | 键值对 |
| XHR | Post | 未设置 | json字符串 | text/plain;charset=UTF-8 | 否 | 能 | 字符串 |
| XHR | Post | 未设置 | a=1&b=2格式字符串 | text/plain;charset=UTF-8 | 否 | 能 | 字符串 |
| XHR | Post | application/x-www-form-urlencoded | a=1&b=2格式字符串 | application/x-www-form-urlencoded | 能 | 否 | 后端收到key为a和b,值为1和2的键值对 |
| XHR | Post | application/x-www-form-urlencoded | json字符串 | application/x-www-form-urlencoded | 能 | 否 | 后端收到一个key为json数据,值为空的键值对 |
| axios | Get | 未设置 | url传参 | null | 能 | 否 | 键值对 |
| axios | Post | 未设置 | json对象 | application/json;charset=UTF-8 | 否 | 能 | json字符串 |
| axios | Post | 未设置 | 数组 | application/json;charset=UTF-8 | 否 | 能 | 数组字符串 |
| axios | Post | 未设置 | a=1&b=2格式字符串 | application/x-www-form-urlencoded | 能 | 否 | 键值对 |
| fetch | Get | 未设置 | url传参 | null | 能 | 否 | 键值对 |
| fetch | Post | 未设置 | a=1&b=2格式字符串 | text/plain;charset=UTF-8 | 否 | 能 | a=1&b=2字符串 |
| fetch | Post | 未设置 | json对象 | text/plain;charset=UTF-8 | 否 | 能 | 后端收到[object Object]字符串 |
| fetch | Post | application/x-www-form-urlencoded;charset=UTF-8 | a=1&b=2格式字符串 | application/x-www-form-urlencoded;charset=UTF-8 | 能 | 否 | 键值对 |
通过上面的表格内容可以发现,凡是使用get或者content-type为application/x-www-form-urlencoded发送数据,在后端servlet都会默认把数据转换为键值对。否则,需要从输入流中获取前端发送过来的字符串数据,再使用fastJSON等后端工具类转换为Java实体类或集合对象。
可以在chrome的应用商店中下载Postman插件,在浏览器中模拟HTTP请求。Postman的界面如下:

说明:
form-data、x-www-form-urlencoded、raw(未经加工的)
类型 Content-Type 说明 form-data Content-Type: multipart/form-data form表单的附件提交方式 x-www-form-urlencoded Content-Type: application/x-www-form-urlencoded form表单的post提交方式 raw Content-Type: text/plain;charset=UTF-8 文本的提交方式
Gitlab 8.x之后默认集成了Gitlab CI,意味着支持了持续集成相关功能。每一次集成操作都需要对应的runner来跑代码构建、测试、发布等操作。Runner实际上就是为Gitlab的持续集成指定一个环境。
Gitlab Runner的版本需要跟Gitlab对应,这里有一个对照表。最新的版本对照表中并没有Gitlab8.X对应的Runner版本,查了一下Gitlab8.X对应的Runner版本为1.X,所以这里选择runner 1.11.2版本。
这里运行Gitlab与Runner的环境均为CentOS,之前尝试在windows上安装runner,对接Linux上的Gitlab,发现在Gitlab runner运行的控制台出现乱码问题。
0.准备
在opt下创建gitlab-runner目录并进入该目录,后续执行的操作与所有的资源都放在这个目录中
1 | cd /opt |
1.下载
下载安装资源到gitlab-runner目录中
1 | sudo wget https://gitlab-ci-multi-runner-downloads.s3.amazonaws.com/v1.11.2/binaries/gitlab-ci-multi-runner-linux-386 |
2.添加运行权限
1 | sudo chmod +x gitlab-ci-multi-runner-linux-386 |
3.创建用户
1 | sudo useradd --comment 'GitLab Runner' --create-home gitlab-runner --shell /bin/bash |
4.安装
1 | ./gitlab-ci-multi-runner-linux-386 install --user=gitlab-runner --working-directory=/opt/gitlab-runner |
经过上面的步骤,Runner就已经跑起来了,剩下的还需要Runner与项目对接起来。Runner的类型分为Shared, specific and group Runners。这里选择specific类型,即单独的项目使用。
在Gitlab项目的setting-runner中,配置过程中会使用到url和token如下所示:
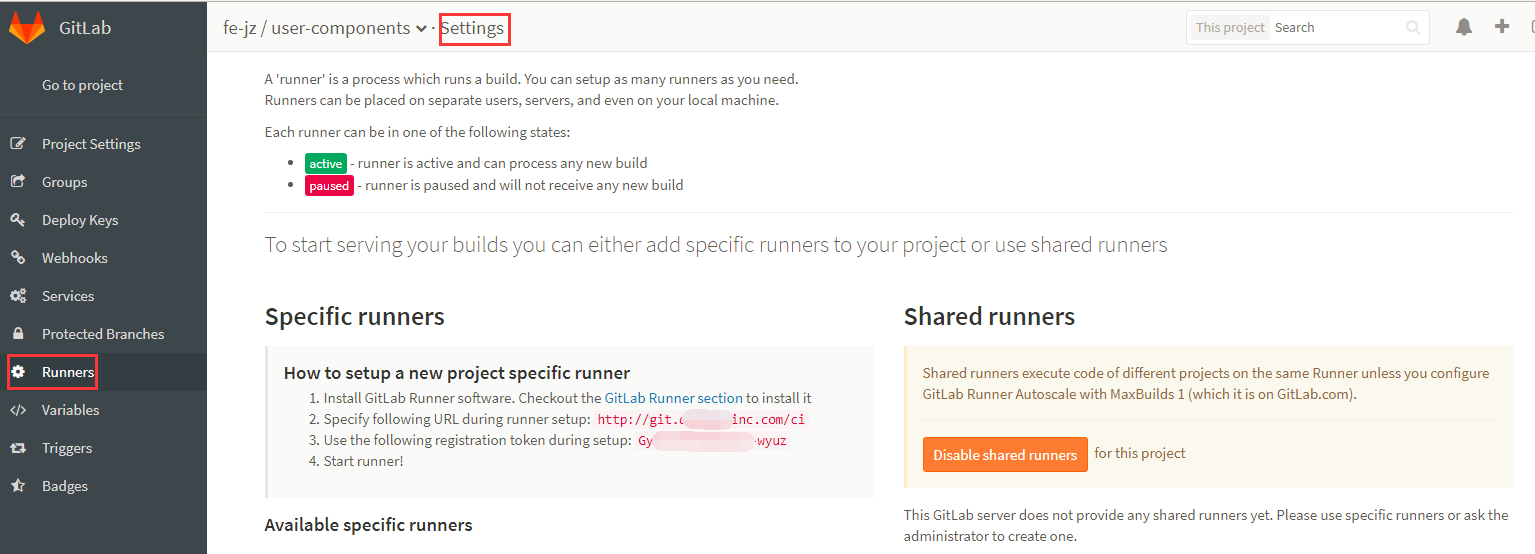
1.运行register命令
1 | ./gitlab-ci-multi-runner-linux-386 register |
之后就按照提示就行了
2.输入url地址
3.输入token
4.输入描述,任意即可
5.输入标签,这里直接Enter跳过
6.选择Runner executor,这里选择shell
到这里就已经注册成功了,输入./gitlab-ci-multi-runner-linux-386 list就能看到上面的注册的条目。
官方文档地址:https://docs.gitlab.com/runner/register/index.html
上面两个步骤做完后,此时按理说Gitlab就能调用Runner跑持续集成了,实际当中还会碰到其它问题,整理如下。
如果在Gitlab的Build控制台上报无法创建文件夹、无法运行bash等,证明创建的GitLab Runner权限不够。
此时,我这里是修改GitLab Runner的权限跟root保持一致。
1 | vim /etc/passwd |
通过上面命令可以编辑用户对应的权限,我这里打开默认为gitlab-runner:x:601:601:GitLab Runner:/home/gitlab-runner:/bin/bash,权限组修改为跟root的一致gitlab-runner:x:0:0:GitLab Runner:/home/gitlab-runner:/bin/bash。(root的权限组名为0)
这里在另外一台机器上还碰到这样修改了也不好使的问题,最终gitlab-runner install的时候,直接指定为root,而不新创建用户。
由于Runner运行需要环境支撑,比如git、node、npm等,需要在Runner所在的服务器上准备好所有的依赖。
1 | # 下载 |
此时,输入node -v就能看到node的版本了。
使用软连接方式可能对非root用户无效,可以转而使用配置环境变量的方式
1 | # 修改配置文件 |
在vim环境下点击i进入插入状态,编辑完成后按Esc键,然后输入 :wq 按回车保存退出。
备注:内外环境还需修改NPM的镜像源,比如修改为npm config set registry https://registry-npm.daojia-inc.com/
1.gitlab-runner帮助:gitlab-runner –help
2.gitlab-runner指定命令帮助:gitlab-runner
3.注册runner:gitlab-runner register
4.注销runner:gitlab-runner unregister
5.当前运行的runner:gitlab-runner list
6.启动runner:gitlab-runner start
7.停止runner:gitlab-runner stop
8.重启runner:gitlab-runner restart
9.查询runner状态:gitlab-runner status
最近UI走查,发现页面中所有包含文字区块的高度与设计稿中的高度完全不一致,然后UI妹子就爆炸了!
找了一下原因,发现是由于UI设计稿中设计的文字大部分是font-size:24px;line-height:24px,代码实现时为了不至于每处都写一遍字体大小,故直接在根节点上统一设置字体与字体大小为24px,小部分不一致的地方再单独设置字体大小,从而忽略了设置line-height为字体的高度。造成的结果就是文字所在的行的行高高于设计稿中的行高。
翻了一下line-height的官方说明,如下所示:
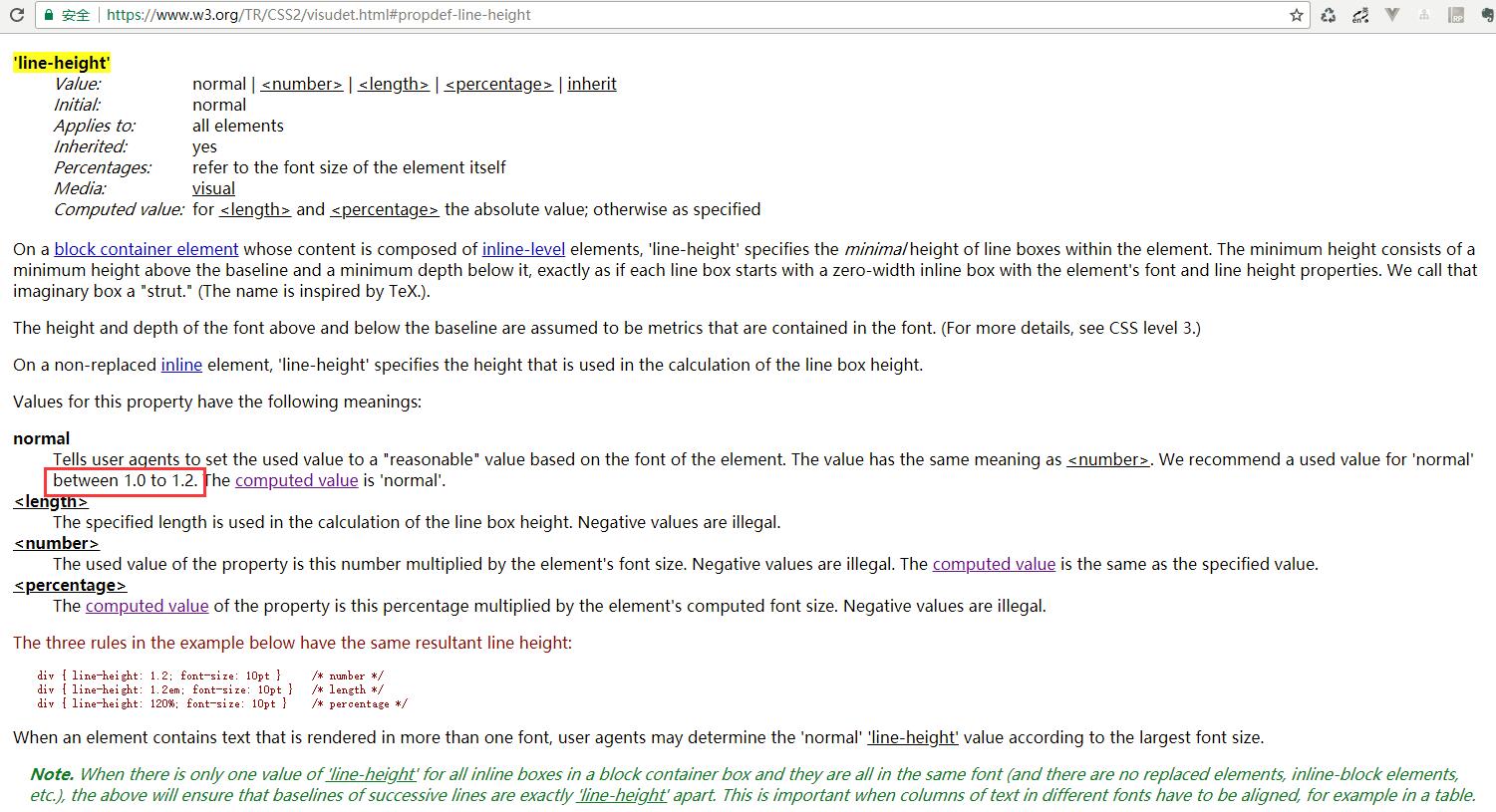
文档里说line-height的默认值为normal,给normal的推荐设置值为1.0到1.2之间。相当于如果设置了字体的大小而不设置line-height,那么行高默认就为字体的1.0-1.2之间的一个倍数。
那么,这个倍数到底具体是多少呢?
在chrome的控制台里跟踪了一下,看到项目中引入了normalize.css来初始化浏览器的默认css样式。其中,就设置html的line-height为1.15。
翻了一下github中normalize.css的issues,在593号issues里找到了答案,地址在这里。
大致过程是这样的,有人发现相同字体与大小的文字在不同环境中line-height的值是不一致的,接着,就有人在crossbrowsertesting上做了个测试,得出的结论就是这个问题的的确确存在,而且差异还特别大
When the font size was 100px, the most common line height was 115px. However, results varied from 101px on Mac Firefox to 136px on Android Chrome.
最终,由于大部分的行高都为115px,所以,为了解决不同环境中相同字体与字号的文字行高不一致的问题,推荐设置默认line-height为1.15
看到这里,想到一个问题,既然显示设置line-height为1.15是为了解决环境兼容的问题。那么,为什么不设置line-height:1即解决兼容问题,又解决由于行高放大与UI设计稿不符的问题? 。
当设置文字line-height:1后,再设置文字所在的容器overflow:hidden很容易复现文字显示不全的问题,比如下面:
代码如下:
1 | <span style=" |
注:这里可以使用div演示,然后去掉display:inline-block。使用div发现不知道为毛markdown里的样例乱了…
到这里,才真正进入到深层次的原因探究。
对于这个问题,需要先了解字体度量,引用一下其它的文章说明,如下所示:
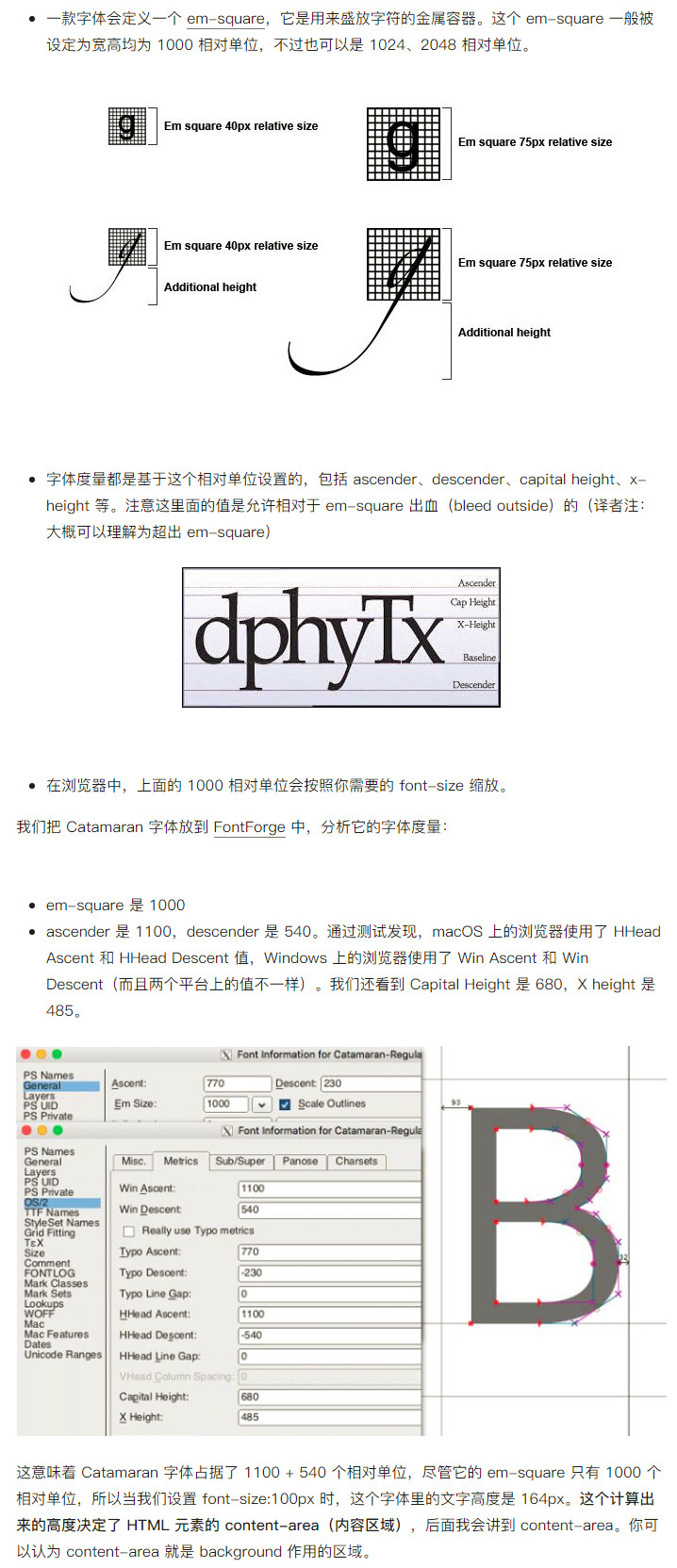
简要解释为如下几点:
font-size的高度实际上是对应字体的EM square部分EM square部分EM square部分一致时,line-height:normal与line-height:1相等ascender+descender>Em Size 即1100+540>1000,此时line-height:1.64,所以100px的文字默认的行高为164px下面就以window环境下的默认字体微软雅黑为例实际看看line-height的计算。
line-height:
代码如下:
1 | <h1 id="font" style="line-height:normal;font-size: 100px;font-family: 微软雅黑">h1</h1> |
从上面可以看到微软雅黑100px情况在,在windows下行高显示为132px。通过FontForge来核对一下看看是不是这样的。

30岁是一道坎。
从年龄上来讲,又是一个十年。人生就这样过完了三分之一,不由得心生感慨!感慨时光如梭,感慨事业无成,感概没有了上一个十年时的锐气,就连眼神也没有了那时的干净清澈。从十年前的白面书生变成了中年油腻男,时间真的是一把杀猪刀!
从工作与生活上来讲,三十而立。但很多人在这个时候面对着上有老下有有小往往却力不从心。需要咬紧牙关坚持下去,翻过这道坎。
就在前几天,我也进入了而立之年。生日当天,那一整天仿佛都充满了仪式感,仿佛过完了那一天就进入到了一个新的人生阶段。当时灵感爆棚(也可能是一时冲动,人很多时候会把冲动当作灵感),希望能记下点什么,但什么都没记下……
今年的315入职新公司,在三十岁之前从传统行业转到互联网行业。之所以转,是因为觉得在传统行业中已经到了天花板,进入了舒适区,不想温水煮青蛙,想换一种环境看看。从目前的情况来看,似乎还不错,在新的环境里有很多事情值得做,值得拼一下。似乎又回到了刚入职场的状态,这是一个之前一直期望的状态,很满意。
30岁不仅仅是一道坎,跨过这道坎实际上是一趟新的征程。希望在这趟新的旅程中能一直坚挺下去!
缺失模块。
1、请确保node版本大于6.2
2、在博客根目录(注意不是yilia根目录)执行以下命令:
npm i hexo-generator-json-content --save
3、在根目录_config.yml里添加配置:
jsonContent:
meta: false
pages: false
posts:
title: true
date: true
path: true
text: false
raw: false
content: false
slug: false
updated: false
comments: false
link: false
permalink: false
excerpt: false
categories: false
tags: true