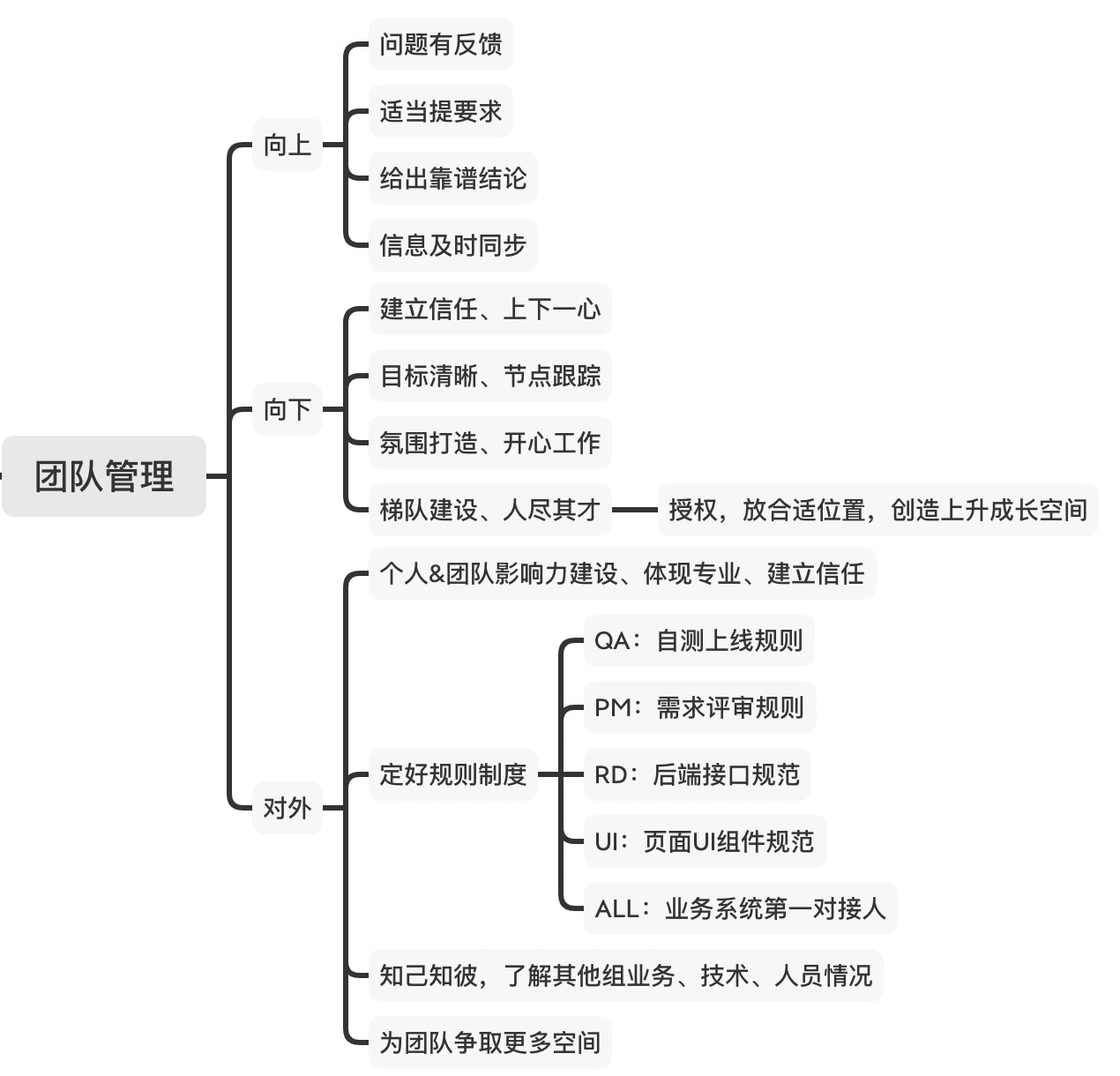
第1章为 什么要用金字塔结构
- 为了交流方便,必须将思想(观点、结论、要点、论点、论据、建议、行动、步骤等)归类分组。
- 将分组后的思想,按照不同层次,进行抽象提炼、总结概括,搭建金字塔。
- 向读者介绍(传递、阐述、论证)思想最有效的途径,是结论先行,自上而下表达。
- 金字塔中的思想,应遵守4个基本原则(见右图)。
- 条理清晰的关键,是把你的思想组织成金字塔结构,并在写作前用金字塔原理检查。
关键概念
金字塔原理的4个基本原则.
· 结论先行:每篇文章只有一个中心思想,并放在文章的最前面。
· 以上统下:每一层次上的思想必须是对下一层次思想的总结概括。
· 归类分组:每一组中的思想必须属于同一逻辑范畴。
· 逻辑递进:每一组中的思想必须按照逻辑顺序排列。
提示
金字塔中的思想以3种方式互相关联一一一向上、向下和横向。位于一组思想的上一个层次的思想是对这一组思想的概括,这一组思想则是对其上一层次思想的解释和支持。
文章中的思想必须符合以下规则:
- 纵向:文章中任一层次上的思想必须是其下一层次思想的概括。
- 横向:每组中的思想必须属于同一逻辑范畴。
- 横向:每组中的思想必须按逻辑顺序组织。
提示
组织思想基本上只可能有4种逻辑顺序:
· 演绎顺序:大前提、小前提、结论
· 时间(步骤)顺序:第一、第二、第三
· 结构(空间)顺序:波士顿、纽约、华盛顿
· 程度(重要性)顺序:最重要、次重要,等等
第2章 金字塔内部的结构
- 金字塔结构的各个层级上包括各种思想;思想使受众(包括读者、听众、观众或学员)产生疑问。
- 在纵向方向上,各分支、各层级上的思想,与读者进行疑问/回答式对话。
- 在横向方向上,各种思想以演绎推理或归纳推理方式回答读者的疑问,但两种方式不可同时使用。
- 序言的讲故事形式是为了提醒读者,文章将回答的读者最初的疑问。
- 序言包括背景、冲突、读者的疑问和作者的回答。冲突因背景而产生,背景和冲突都是读者已知的事实。
- 冲突导致读者提出疑问,而文章将回答读者的疑问。
关键概念
金字塔结构中的逻辑关系
· 各种思想纵向相关(疑问/回答式对话)
· 各种思想横向相关(演绎/归纳,MECE原则)
· 金字塔顶端思想回答的疑问,来自读者已知的事实
· 序言引出读者最初的疑问
提示
金字塔中的子结构,能够加快你梳理思想的过程。
· 主题与子主题之间的纵向关系
· 各子主题之间的横向关系
· 序言的叙述方式
这三种子结构(即纵向的疑问/回答式对话、横向的演绎或归纳逻辑、讲故事式的序言结构)能够帮助你找到构建金字塔所需的思想。
了解了纵向关系,你就可以确定某一层次上的思想组必须表达哪种信息(即:必须回答针对上一层次思想提出的疑问)。
了解了横向关系,你就可以判断,你组织在一起的思想是否以符合逻辑的方式表达了这种信息(即:是否是正确的归纳或演绎论述)。
更重要的是,了解读者最早提出的问题,将确保你组织起来的思想与读者有关联(即:文章中的思想有助于回答读者的初始问题)。
第3章 如何构建金字塔
自上而下法
· 确定作者想论述的主题
· 设想读者的疑问
· 给出答案
· 检查背景和冲突是否引发读者提出疑问
· 证实答案
· 填写关键句要点
提示
自上而下法构建金字塔的步骤
· 提出主题思想
· 设想受众的主要疑问
· 写序言:背景-冲突-疑问-回答
· 与受众进行疑问/回答式对话
· 对受众的新疑问,充分进行疑问/回答式对话
自下而上法
· 列出所有作者想表达的要点
· 找出各要点之间的关系
· 得出结论
· 到推出序言
- 如果读者在阅读的最初30秒内还不能清楚了解你的全部思路,你就应该重写这篇文章。
- 如果文章较长,用小标题。标题应呈现某种思想、观点或结论,而不只说明要讨论问题的类别,例如,不要用“我们的发现”,“结论”这类的标题。因为对于读者快速了解文章的主要内容和观点没有太大帮助。
关键概念
构建金字塔
- 确定主题
- 设想疑问
- 给出答案
- 检查背景和冲突是否引发读提出疑问
- 证实答案
- 填写关键句要点
初学者注意事项
- 一定先搭结构,先尝试自上而下法
- 序言先写背景,将背景作为序言的起点
一旦你知道自己想在序言的主体部分说些什么——情境、冲突、疑问和回答――你就可以根据你想产生的效果,以任何顺序写出这些要素。
- 先多花时间思考序言,不要忽略对序言部分的思考
- 将历史背景放在序言部分
- 序言部分仅涉及读者不会对其真实性提出怀疑的内容
序言的目的只是告诉读者一些他们已经知道的信息。
- 在关键句层次上更宜使用归纳法而非演绎法
第4章 序言的具体写法
- 序言的目的是提示读者已知的信息,而不是提供新信息。
- 序言通常包括背景、冲突、读者的疑问和作者的答案。
- 序言的长短,取决于读者的需要和主题的要求。
- 为每个关键句要点写一段引言
关键概念
写序言
· 说明背景(S, Situation)
· 指出冲突(C, Complication)
· 冲突引发读者提出疑问(Q,Question)
· 作者的文章给出答案(A,Answer)
序言基本结构
序言必须采取“背景(S)—冲突(C)— 疑问(Q)— 回答(A)”的结构,但是各个部分的顺序可以有所变化。
· 标准结构:背景 – 冲突 – 答案
· 开门见山式结构: 答案 – 背景 – 冲突
· 突出忧虑式:冲突 – 背景 – 答案
· 突出信心式:疑问 – 背景 – 答案
第5章 演绎推理与归纳推理
- 演绎推理是一种论证,其中第二个论点对第一个论点加以评论,第三个论点说明前两个论点同时存在时的含义。
- 对演绎推理的概括,就是把最后一个论点作为主体,概括整个推理过程。
- 归纳推理是把具有相似性的思想归类分组,根据各要点具有的共同性得出结论。
- 在关键句层次,使用归纳推理比演绎推理更方便读者理解。
关键概念
逻辑推理
· 演绎推理,是一系列线性推理过程。
· 归纳推理,是把相似的、具有共同点的思想或相关的行动归类分组。
· 在关键句要点层次,使用归纳推理,比演绎推理更利于读者理解。
记住:当你进行演绎推理时,推理过程的第二个思想必须是对第一个思想的主语或谓语的评述。如果不具备这一点,就不是演绎推理而是归纳推理。
提示
用归纳法时,必须具备以下两项主要技能:
· 正确定义该组思想。找到一个能够表示该组所有思想共同点的名词。
· 识别并剔除改组四中与其他思想不相称(不属同类、不具备共同点的思想)
提示
演绎推理与归纳推理的区别
演绎推理:第二点是对第一点主语或谓语的论述。
归纳推理:同组中的思想具有类似的主语或谓语。
第6章 应用逻辑顺序
- 应用逻辑顺序可以确你不会:
- 任一组思想的逻辑顺序都呈现了该组思想的分组基础。
- 时间顺序:通过设想某一流程,得出的思想
- 结构顺序:通过评论某一结构,得出的思想。
- 程度顺序:通过按程度或重要性不同分组,得出的思想
- 如果你在某一组思想中找不到以上顺序,说明这些思想之间不存在逻辑关系,或者你的思考还不周全。
- 为了检查一组思想的逻辑顺序,你可以:
- 先把每一个句子改写成能说明其实质的短句(即只保留主语、谓语、宾语,删除定语、状语和补,只保留动词、名词,删除形容词、副词)。
- 再把相匹配或具有共同点的句子合并同类项,组织在一起。
- 最后选择使用适当的顺序。
- 如果思想属于行动性思想(即说明行动、活动、行为、动作、步骤、流程等)
- 明确说明每一行动产生的最终结果(效果、目标)
- 把能产生同样最终结果的行动(行为、步骤等)归类分组
- 确定该组思想的分组基础(类别),并依此排序。
- 检查是否遗漏了任何步骤。
- 如果思想属于描述性思想(即介绍观点、情况、信息等)
- 把说明类似事务,或具有共同点的思想归类分组。
- 确定该组思想的分组基础(找出相似之处、共同占)
- 把所有思想转换成完整的句子,并决定其顺序。
- 检查是否遗漏了任何步骤。
关键概念
将行动性思想(说明行动、活动、行为、步骤、流程)排序.
- 明确说明每一行动产生的最终结果。
- 把能产生相同最终结果的思想合并、归类、分组。
- 确定该组思想的分组基础,并依此排序。
- 检查是否遗漏了任何步骤。
关键概念
将描述性思想(介绍观点、论点、论据、情况、信息)排序
- 把说明类似事务、或具有共同点的思想归类、合并、分组。
- 确定该组思想的分组基础。
- 把所有思想转换成完整的句子,并决定其顺序。
- 检查是否遗漏了任何步骤。
第7章 概括各组思想
- 避免使用“缺乏思想”的句子(比如“存在3个问题·一··”等)
- 分组应遵守“相互独立不重叠,完全穷尽无遗漏”(MECE)原则。
- 行动总是按时间顺序进行,通过说明行动产生的直接结果,概括行动性思想。
- 把描述性思想归类分组,是因为该组思想具有共同特生它们都:
- 针对同一类主语一针对同一类谓语(动作或对象)一包含同一类判断
- 将行动性思想分组时,要求:
- 发掘每一个行动的本质
- 区分不同的抽象层次(比如,采取一项行动,是必须在另一行动开始之前,还是为了完成另一行动?)
- 明确说明行动产生的最终结果
- 直接由行动概括出结果
- 将描述性思想分组时,要求:
- 找出句中结构的共同点
- 确定包括这些思想的最小范畴
- 说明共同点隐含的意义
关键概念
概括各组思想
- 通过说明行动产生的直接结果,概括行动性思想(概括一组行动)。
- 通过说明各思想具有的共同点、相似性,概括描述性思想(概括一组信息)。
关键概念
寻找思想的共同点
- 各思想是否针对同一类主题
- 各思想是否涉及同一类行动
- 各思想是否针对同一类对象
- 各思想是否包含同一类观点
关键概念
行动性思想分组
- 发掘每个行动的实质
- 区分行动的不同层次
- 明确说明行动性思想产生的最终结果(效果、目标)
- 直接由行动概括出结果
关键概念
描述性思想分组
- 找出主语、谓语、宾语或含义的共同性
- 确定包括这些思想的最小范畴
- 说明共同性隐含的意义
第8章 界定问题
- 展开“问题”的各要素
- 切人点/序幕(产生问题的具体领域、方面)
- 困扰/困惑(它的发生打乱了该领域的稳定)
- 现状R1(你不喜欢该方面正在产生的结果)
- 目标R2(你希望在该方面得到的结果)
- 答案(到目前为止,针对问题已经采取的措施,如果采取了的话)。
- 把界定的问题转换成序言
关键概念
界定问题
- 设想问题产生的领域
- 说明什么事情的发生打乱了该领域的稳定(困扰/困惑)
- 确定非期望结果(现状,R1)
- 确定期望结果(目标,R2)
- 确定是否已经采取了解决问题的行动
- 确定分析所要回答的疑问
- 疑问(为了解决问题,必须做什么)
第9章 结构化分析问题
- 使用诊断框架,呈现存在问题领域的详细结构,展示一个系统内的各个单位是如何相互影响的。
- 查找具有因果关系的活动
- 将产生问题的可能原因进行分类
- 收集资料,以证明或排除结构中导致问题产生的部分
- 使用逻辑树
关键概念
结构化分析问题
- 界定问题
- 使用诊断框架,呈现存在问题领域的详细结构
- 假设产生问题的可能原因
- 收集信息,以证明或排除所作假设
第10章 在书面上呈现金字塔
用多级标题、行首缩进、下划线和数字编号的方法,突出显示文章的整体结构
- 表现金字塔结构中主要组合之间的过渡
- 表现金字塔结构中主要思想组之间的过渡
第11章 在PPT演示文稿中呈现金字塔
- 制作文字幻灯片,尽量简明扼要
- 制作图表幻灯片,使传达的信息更简单易懂
- 使用故事梗概,简要说明整体结构
- 排练排练,再排练。
第12章 在字里行间呈现金字塔
- 画脑图(在大脑中画图像,或画思维导图)
- 把图像复制成文字







留言
欢迎交流想法。留言会通过 GitHub Issues 保存,首次使用需要登录 GitHub。